and the distribution of digital products.
Your LLM Stack Is Not Ready for Production—Here’s What You’re Missing
Generative AI and large language models in particular are no longer side projects or mere APIs. They demand a new style of engineering and a new organizational discipline. The core issue isn’t just technical novelty. LLMs replace determinism with probability, introduce a “linguistic interface” as the new application layer, and demand that leaders rethink how systems are built, validated, and maintained at scale.
What truly sets this shift apart is the emergence of a new architectural dimension - uncertainty itself. In LLM-driven systems, unpredictability isn’t a minor annoyance or an edge case: it becomes the primary design challenge at every level. Prompt interpretation, agent interactions, orchestration logic, and even the boundaries of model attention are all sources of ambiguity that must be engineered for, not simply controlled or avoided. This new dimension fundamentally changes the craft of software architecture, requiring teams to build systems that can adapt, recover, and learn from inevitable drift and unpredictability.
It’s tempting to think that AI leadership is about having the largest, flashiest language model or the biggest context window. But that’s a myth. The real competitive edge goes to teams who master the architecture - those who build, refine, and govern the entire LLM stack: prompt engineering, modular agents, orchestration, and retrieval. In this new era, sustainable AI success is less about raw model power and more about the collective discipline, learning, and operational depth of your engineering team.
Why This Shift Is Different
- From Predictable Code to Adaptive Language. In classic systems, you controlled every input and output. With LLMs, you orchestrate behaviors in a living, evolving environment where outputs depend on training, context, and prompt design, not hardwired logic.
- No More Silver Bullets. Every model, prompt, and integration brings trade-offs. Architecting for diversity and change is now the rule, not the exception.
- Experience Over Rulebooks. Technical skill is no longer about memorizing static rules, but about navigating ambiguity, risk, and rapid iteration across a stack that is both more powerful and less predictable.
What Should Leaders Actually Do?
- Prioritize LLM Architecture. Make it a board-level topic. Treat LLM systems as strategic infrastructure.
- Invest in Adaptive Teams. Build engineering and product teams that are comfortable working across multiple models, rapid prototyping, and fast feedback loops.
- Put Quality and Guardrails First. Version, review, and test every prompt. Implement layered validation and privacy controls early, not as an afterthought.
- Upskill Continuously. LLMs demand new skills for everyone - from product owners to architects. Make “learning the stack” a recurring priority.
Bottom Line: LLMs aren’t a productivity add-on. They are becoming the new foundation for scalable software, where adaptability and reliability matter as much as raw capability. The winners will be those who master this complexity - not those who simply add another tool to the stack.
Architectural Inflection Point: From Code to ConversationFor decades, software evolved through a sequence of predictable layers: monoliths to microservices, tightly controlled APIs to event-driven flows. Each step improved modularity and scale but relied on strict contracts, explicit error paths, and logic you could debug line by line.
LLMs break that pattern. Now, the system’s most important behaviors—logic, validation, even knowledge retrieval - are written in natural language, not just code. Prompts, not function calls, become the API. What was once coded is now designed, tested, and evolved through conversation and example.
What Really Changes:
- The Input/Output Contract Is Gone. In LLM systems, the answer is a probability distribution, shaped by both prompt and context. A small change in wording can mean a big change in behavior.
- Logic as Content. Key decisions, business rules, and even regulatory checks are embedded in prompt assets. These can be managed by non-developers - and drift, mutate, or “rot” outside the codebase if not carefully versioned.
- Ambiguity Becomes the Norm. Debugging moves from code inspection to prompt analysis and context tracing. New failure modes emerge: prompt drift, knowledge staleness, output hallucination.
Why This Demands a New Mindset
Old patterns - building for determinism, relying on a single source of truth, expecting static validation - no longer work. Instead, modern architecture is about resilience:
- Layering guardrails and validation across prompts, orchestration, and code.
- Designing for ambiguity and fast recovery, not just control.
- Engineering for constant learning and safe iteration.
The Real Inflection Point: Architects now operate more like conductors than controllers, managing dynamic, adaptive systems. The best teams don’t try to eliminate uncertainty - they design processes and stack layers that thrive on it.
The Foundation Blueprint: Three Tiers of Modern LLM ArchitectureAs LLMs become foundational to business software, their architecture has crystallized into three tightly integrated tiers. This structure isn’t about adding complexity for its own sake -each layer solves unique challenges, and skipping any one leads to the same production failures, no matter the size of your company.
1. The Prompt Layer: Language as the InterfaceThe Prompt Layer is the direct interface with the model - where logic, rules, and constraints are encoded in natural language, not just code.
Managing uncertainty in how the model will interpret, generalize, or drift from the prompt intent.
What it enables:
- Translates business intent into LLM-understandable tasks: Every prompt defines not just what to do, but how.
- Encodes logic and validation: Prompts can enforce formats, sanity checks, and guardrails directly.
Failure modes:
- Hallucinations & inconsistency: Vague or overloaded prompts generate unpredictable outputs.
- Prompt debt: Untracked changes, hidden business logic, or duplicated templates quickly become unmanageable.
- Cost blowups: Verbose or inefficient prompts inflate token usage and operating expenses.
Actionable tip: Treat prompts as code - version them, test them, and monitor for drift.
2. The Agent Layer: Modular ExpertiseThe Agent Layer introduces modularity and specialization. Agents are like skill plugins - they encapsulate roles such as retriever, summarizer, validator, or workflow manager.
Uncertainty multiplies as logic is distributed across agents - handoff, role boundaries, and context sharing all add new degrees of freedom and risk.
What it enables:
- Separation of concerns: Each agent owns one responsibility - search, parsing, validation, orchestration, etc.
- Role-based logic and security: Access and decision boundaries are enforced per agent.
- Advanced knowledge retrieval: In mature stacks, agents directly invoke RAG for targeted, up-to-date knowledge.
Failure modes:
- Agent sprawl: Overlapping, poorly documented agents cause chaos and dependency hell.
- Security leaks: Agents without strict isolation or data boundaries risk sensitive information exposure.
- Debugging hell: Tracing issues across a “swarm” of agents with hidden dependencies is painful without centralized logs and clear contracts.
Actionable tip: Keep agents small, auditable, and well-documented - review agent roles as carefully as code modules.
3. The Orchestration Layer: Adaptive Workflows and RAGAt the top, the Orchestration Layer acts as the “conductor” of the stack. It coordinates how agents and LLM calls flow, manages state, enforces business logic, and connects to Retrieval-Augmented Generation (RAG).
Orchestrating uncertainty itself: dynamically routing tasks, maintaining fragile state, recovering from failures that have no deterministic path.
What it enables:
- Complex workflows: Multi-step processes across agents, external APIs, and knowledge bases.
- Centralized compliance and audit: Business rules, validation, and logging are handled globally.
- Dynamic context enrichment: RAG brings the latest, most relevant knowledge into every interaction - both system-wide and at the agent level.
Failure modes:
- Workflow drift: Poorly maintained orchestration grows brittle and opaque; failures become hard to detect or fix.
- RAG drift: Retrieval patterns left unchecked yield stale or irrelevant results - output quality drops silently.
- State loss: If state isn’t robustly managed, context and conversation get lost, leading to random or repeated failures.
Actionable tip: Make orchestration explicit, observable, and testable - never rely on LLM “memory” for state or workflow integrity.
Connecting the TiersEach layer multiplies the others’ value.
- Prompts define logic, but only modular agents keep it maintainable.
- Agents enable specialization, but only orchestration ties it all together at scale.
- RAG turns static LLMs into living, business-aware systems - but only if managed through reliable workflows.
Bottom line: Skip a layer, and your system will eventually break - either by cost, chaos, security, or simple unmaintainability. Master all three, and you build the real foundation for modern, adaptive, and safe AI-powered delivery.
\
A Mindset Shift: Composing, Specializing, Navigating UncertaintyWhat unites these layers is not a single “best practice,” but a new engineering mindset. Modern LLM architecture is about composition (building systems from interoperable modules), specialization (assigning clear responsibilities), and, most of all, managing uncertainty at every step.
Success now requires hybrid, cross-disciplinary teams. Prompt engineering, agent design, orchestration, and retrieval are distinct skillsets - no single role can cover them all. The best teams blend linguistic precision, workflow design, and system-level thinking, and they are relentless about monitoring, validating, and evolving their stack.
This layered approach is not optional; it’s the only way to scale LLM-powered systems reliably, securely, and sustainably.
Prompt Engineering (Prompt Layer): The New API SurfaceIn modern LLM architectures, prompt engineering is no longer a side skill - it’s the primary interface layer, shaping logic, guardrails, exception handling, output templates, and even cost. Where classic APIs provided deterministic contracts, prompts define behavior and boundaries in natural language - introducing both flexibility and risk.
Patterns: Instructional, Few-Shot, Chain-of-Thought, Modular, and Beyond- Instructional prompts: Direct, step-by-step instructions for the model.
- Few-shot prompts: Providing multiple examples to steer output consistency.
- Chain-of-thought: Encourages the model to reason step-by-step, improving reliability in multi-stage tasks.
- Modular prompting: Decomposing logic into reusable, composable prompt blocks.
But prompt patterns are evolving fast. Advanced prompts can:
- Express loops and recursion: By instructing the model to “repeat until” a condition is met, or to apply reasoning recursively across a data structure. This opens the door to iterative logic previously reserved for traditional code.
- Manage state: Prompts can explicitly carry forward previous answers, partial results, or metadata, making conversations and workflows stateful. State can be passed either via context (“As previously discussed, …”) or embedded as variables in templated prompts.
This flexibility means prompts can encode not just static instructions, but dynamic behaviors that rival traditional scripting - without writing code.
Why Disciplined Prompt Design is Non-NegotiableWith great power comes a maintenance burden. Poorly designed prompts invite:
- Unpredictable outputs (“prompt drift”)
- Hidden dependencies on phrasing or example order
- Escalating costs from inefficient, verbose instructions
- Security risks and output leakage
Scaling LLM-driven systems demands that prompts are treated like first-class software artifacts: reviewed, versioned, tested, and documented.
Engineering Practices- Versioning: Store prompts in source control, with code reviews for every change.
- Testing: Maintain prompt input/output test cases - catch drift, regression, and hallucinations early.
- Orchestration: Integrate prompts into workflow engines, supporting chaining, retries, and rollback on failure.
- Guardrails: Use explicit instructions and output formatting (e.g., “If you are unsure, answer ‘Unknown’”; require JSON or other structured output).
Anti-patterns:
- Vague, multi-purpose prompts (“Tell me about this.”)
- Overloading prompts with too many instructions (“Summarize, translate, analyze, and explain the risks - all at once”)
- Lack of clear output specification (free-form, inconsistent responses)
A robust prompt engineering practice turns ad-hoc instructions into a maintainable, scalable system.
Best Patterns and Integration Methods- Chaining: Break down complex workflows into stepwise prompts, passing state/results from one stage to the next.
- Modularity: Build libraries of reusable prompt templates for repeated logic or structure.
- Templating and Parameterization: Use placeholders/variables for context-specific data, enabling prompts to adapt across use cases without rewriting.
Code example: prompt_template = "You are a project manager. Based on this project brief: {brief}, list all identified risks and mitigation strategies."
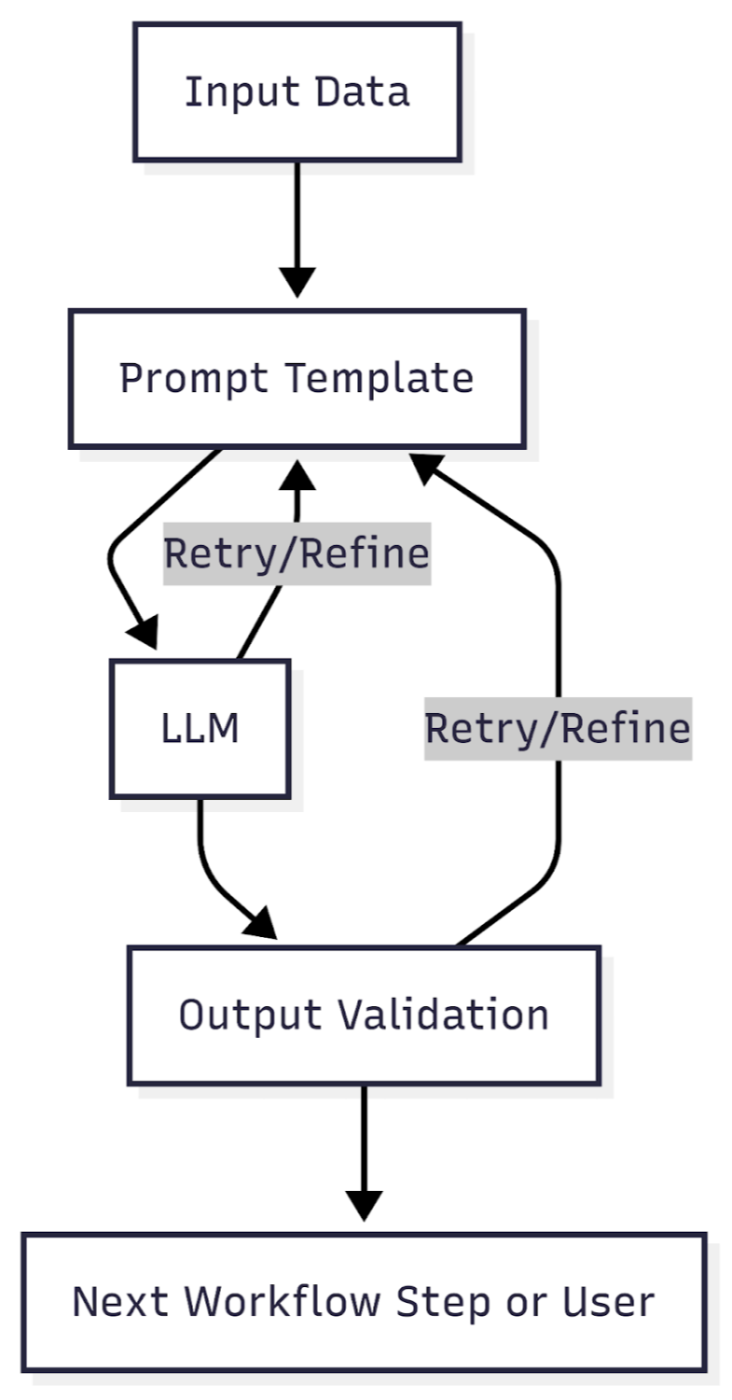
Exception Handling and Quality Control- Detect and escalate failures: Catch empty, contradictory, or out-of-format outputs; trigger retries, fallback prompts, or human review.
- Validation layers: Automatically parse and check outputs - enforce formats, required fields, and business rules.
- Monitoring: Track accuracy, cost per request, error rates, and performance trends.
- Design → Review → Test → Deploy → Monitor → Refine
Diagram:
\
Common Errors- Ignoring prompt versioning: leads to “ghost bugs” and silent regressions.
- Hardcoding data/context into prompts instead of using templating.
- Failing to monitor output quality and drift as models update over time.
Prompt engineering today is not just about writing clever instructions - it’s about building a rigorous interface layer, with as much care and process as traditional API or business logic development. Modern prompts can express cycles, manage state, and power dynamic, adaptive systems - if designed and managed with engineering discipline.
The Agent Layer: Role, Specialization, ResponsibilityAs LLM-powered systems mature, the single “mega-prompt” approach quickly breaks down. The solution is the Agent Layer - a modular, composable layer that encapsulates distinct responsibilities, domain expertise, and logic. Agents represent both a unit of separation (think: microservices, but for reasoning and interaction) and a critical surface for enforcing security and operational guardrails.
Why Agents? Modularity, Specialization, and BoundariesIn the agent layer, each agent acts as a specialist:
- Separation of concerns: Agents are assigned discrete roles - summarizer, data retriever, validator, workflow manager, etc. - mirroring real-world expertise.
- Role-based logic: Each agent encodes logic and decision patterns optimized for its task, reducing complexity and improving maintainability.
- Security boundaries: By isolating tasks, agents can enforce clear input/output boundaries, access controls, and even privacy policies - limiting blast radius and potential data leakage.
A major evolution in agent architecture is direct invocation of Retrieval-Augmented Generation (RAG) modules:
- Targeted knowledge retrieval: Agents can fetch only the context they need, optimizing token usage and reducing noise.
- Adaptive specialization: Some agents use basic LLM capabilities, while others invoke RAG or external tools for deeper, more accurate knowledge injection.
- Cost and efficiency: Instead of passing massive context to every prompt, RAG-enabled agents operate with precision - lowering costs and improving response quality.
RAG’s Role: At this layer, RAG isn’t just a backend service; it becomes part of the agent’s “toolkit” - each agent can query knowledge bases, document stores, or APIs as needed for its specific sub-task.
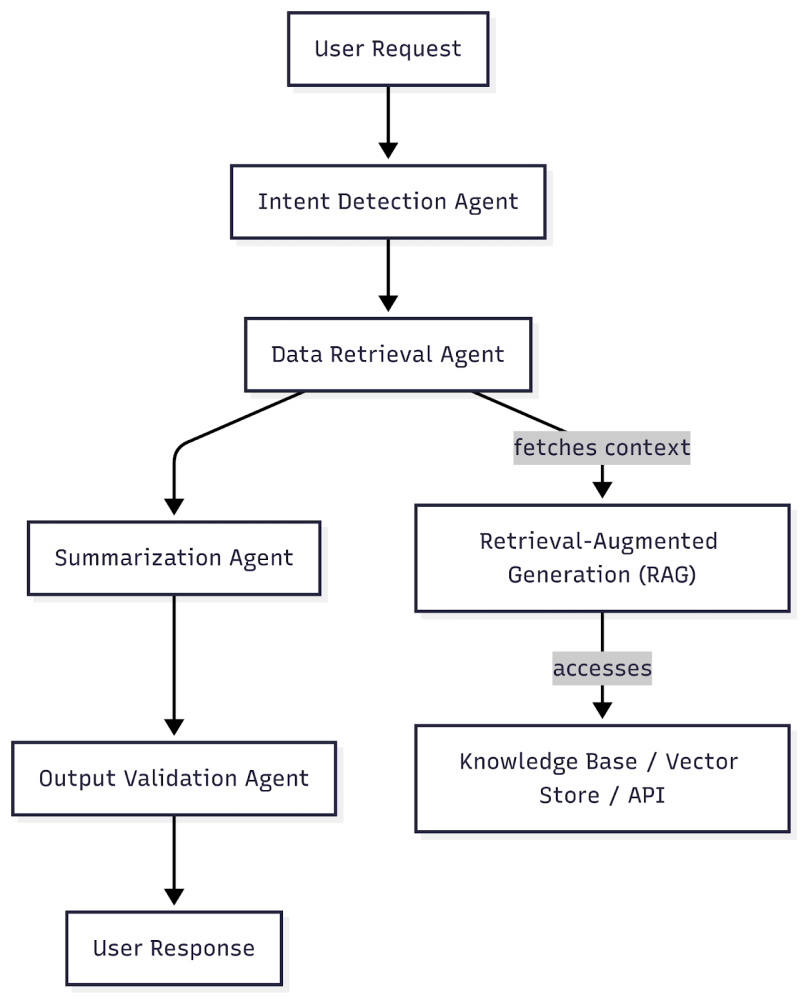
Patterns for Agent Composition and Responsibility- Single-responsibility agents: Each agent does one thing well (e.g., extract entities, validate facts, perform classification).
- Agent orchestration: Multiple agents collaborate in sequence or parallel, managed by an orchestration layer or workflow engine.
- Hybrid agents: Some agents blend LLM capabilities with deterministic logic or retrieval tools, adapting to context and task.
Example workflow:
- Least privilege: Limit each agent’s data access to only what is necessary.
- Audit and traceability: Log agent actions, requests, and data flows for monitoring and compliance.
- Isolation: Run sensitive or high-risk tasks in sandboxed agents, preventing leakage across boundaries.
- Cost controls: Track per-agent token and API usage, allowing fine-grained budgeting and throttling.
- Enterprise search: One agent handles query parsing, another retrieves documents via RAG, a third summarizes results.
- Regulatory compliance: Agents handle redaction, data validation, and policy enforcement before anything reaches the user.
- Customer support bots: Specialized agents handle intent, escalation, personalization, and context retrieval - each with isolated logic and data access.
The Agent Layer transforms monolithic prompt logic into a scalable, modular architecture - mirroring the way modern software decomposes complexity. By leveraging agents for separation, specialization, and security, organizations build LLM systems that are not just more powerful, but also safer, cheaper, and easier to maintain.
The Orchestration Layer: Workflow, RAG, and Future-ProofingAs LLM-powered systems grow in scope and complexity, reliable delivery can no longer depend on isolated prompts or single agents. The Orchestration Layer becomes the architectural backbone - a “conductor” that manages workflows, business logic, state, guardrails, and integrations across the entire stack.
Orchestration: The System’s Nervous CenterThe Orchestration Layer coordinates every moving part:
- Workflow management: Orchestrates the handoff between agents, LLM calls, retrieval modules, and external APIs.
- State management: Tracks the conversation, user context, intermediate results, and workflow progression. This is critical for multi-turn tasks, context-aware operations, and long-running business processes.
- Guardrails and business logic: Enforces policies, validation steps, exception handling, and compliance requirements - ensuring outputs are both accurate and safe.
Key difference: In traditional architectures, workflows are coded as pipelines or process engines. With LLMs, orchestration must also manage probabilistic behaviors, ambiguous outputs, and dynamic branching, often “adapting on the fly.”
RAG: The Knowledge EngineRetrieval-Augmented Generation (RAG) is at the heart of this layer. Orchestration determines when and how to:
- Pull in relevant data from knowledge bases, vector stores, or APIs.
- Filter, validate, and enrich context before passing it to LLMs or agents.
- Control retrieval costs, reduce “hallucination” risks, and optimize for relevance.
Dual roles for RAG:
- Systemic: Centralized knowledge retrieval for the entire workflow - injecting global context, updating knowledge in real time.
- Agent-level: Targeted retrieval for specific sub-tasks - allowing agents to operate with minimal, high-precision context.
Common patterns:
- Sequential orchestration: Linear chains of tasks/agents (e.g., parse → retrieve → summarize → validate).
- Parallel orchestration: Multiple agents/processes run concurrently (e.g., extracting different entities or insights in parallel).
- Conditional branching: Dynamic workflow steps based on intermediate LLM outputs or user actions.
Pitfalls to avoid:
- State loss: Failing to persist or pass context between steps leads to broken conversations and “dumb” workflows.
- Opaque workflows: Without clear logging, tracing, and monitoring, it’s nearly impossible to debug or improve system behavior.
- RAG drift: Uncontrolled retrieval queries may bring irrelevant or outdated context, causing output degradation over time.
- Explicit state management: Persist conversation and task states in structured stores; never rely on LLM memory alone.
- Output validation: Integrate validation layers, both rule-based and LLM-powered, to catch errors, hallucinations, and formatting issues.
- Versioned workflows: Treat orchestration logic as code: versioned, tested, and monitored.
- Continuous monitoring: Log every workflow step, measure accuracy, latency, and cost; set up alerts for anomalies or failures.
- Composable orchestration: Build workflows as modular, reconfigurable components: future updates or model swaps should not require rewriting the entire pipeline.
The Orchestration Layer is the difference between brittle demos and robust, production-grade LLM systems. By managing workflows, state, and contextual knowledge—powered by well-governed RAG—organizations create AI solutions that are not just smart, but reliable, scalable, and ready for whatever’s next.
RAG (Retrieval-Augmented Generation) In-DepthRAG sits at the intersection of LLM flexibility and the need for precise, up-to-date, and context-rich knowledge injection.
Why RAG? Addressing Context Limits and Dynamic Knowledge NeedsLLMs, no matter how large, have fixed context windows and a static “knowledge cutoff” based on their last training data.
- Context limits: Even the largest models can process only a few dozen pages at a time, far less than most enterprise knowledge bases or real-world document sets.
- Stale knowledge: Without retrieval, LLMs can’t answer questions about new policies, fresh documents, or changing environments.
RAG solves these challenges by giving the LLM access to external, up-to-date sources - enabling dynamic, targeted knowledge injection at inference time.
How RAG Works: The Engine Under the Hood- Retrieval: Given a user query or workflow prompt, the system uses search (semantic/vector search, keyword, hybrid) to fetch the most relevant documents, facts, or data snippets from one or more external sources (databases, APIs, file systems, etc.).
- Filtering: Retrieved results are ranked, filtered, and sometimes condensed - removing noise, duplicates, or irrelevant context.
- Context construction: The curated context is formatted (as passages, snippets, or structured data) and appended to the user’s prompt or agent input.
- LLM Integration: The LLM receives the enriched prompt, now grounded in both its own knowledge and the latest retrieval results, and generates a final answer or action.
Example flow:
- User asks about a policy.
- System retrieves the latest document from the policy KB.
- LLM answers, referencing the new data, not just its training set.
- Systemic RAG: Retrieval is managed centrally, feeding all agents/workflows from a single knowledge engine.
- Agent-accessible RAG: Individual agents call retrieval modules directly, tailoring queries to their sub-tasks.
- Knowledge curation: Regularly index, clean, and deduplicate source data; set up robust update pipelines.
- Query optimization: Tune search algorithms for both recall and precision. Avoid “over-stuffing” context windows.
- Output validation: Always cross-check LLM output against the retrieved facts, flag answers not directly supported by the context.
- Traceability: Log which sources were used for every response. This is essential for audits, debugging, and compliance.
- Query drift: As prompts or tasks change, retrieval patterns may become too broad or too narrow, missing relevant info or injecting noise.
- Stale retrieval: If knowledge bases aren’t updated or old data isn’t pruned, LLMs can confidently hallucinate obsolete facts.
- Context overload: Too many retrieved passages dilute answer quality and can push out essential details due to context window limits.
- Precision and recall metrics: How often is the correct info retrieved and used?
- Cost tracking: Monitor retrieval API and LLM token usage per request.
- Latency measurement: Ensure RAG doesn’t become a system bottleneck.
- Auditability: Every LLM output should be traceable back to its supporting context.
RAG is the engine that bridges LLM intelligence and real-world, ever-changing knowledge. When designed and maintained with discipline, RAG transforms LLMs from closed-box guessers into reliable, context-aware problem solvers. But RAG is not “set and forget” - it’s an active system that demands regular curation, monitoring, and optimization.
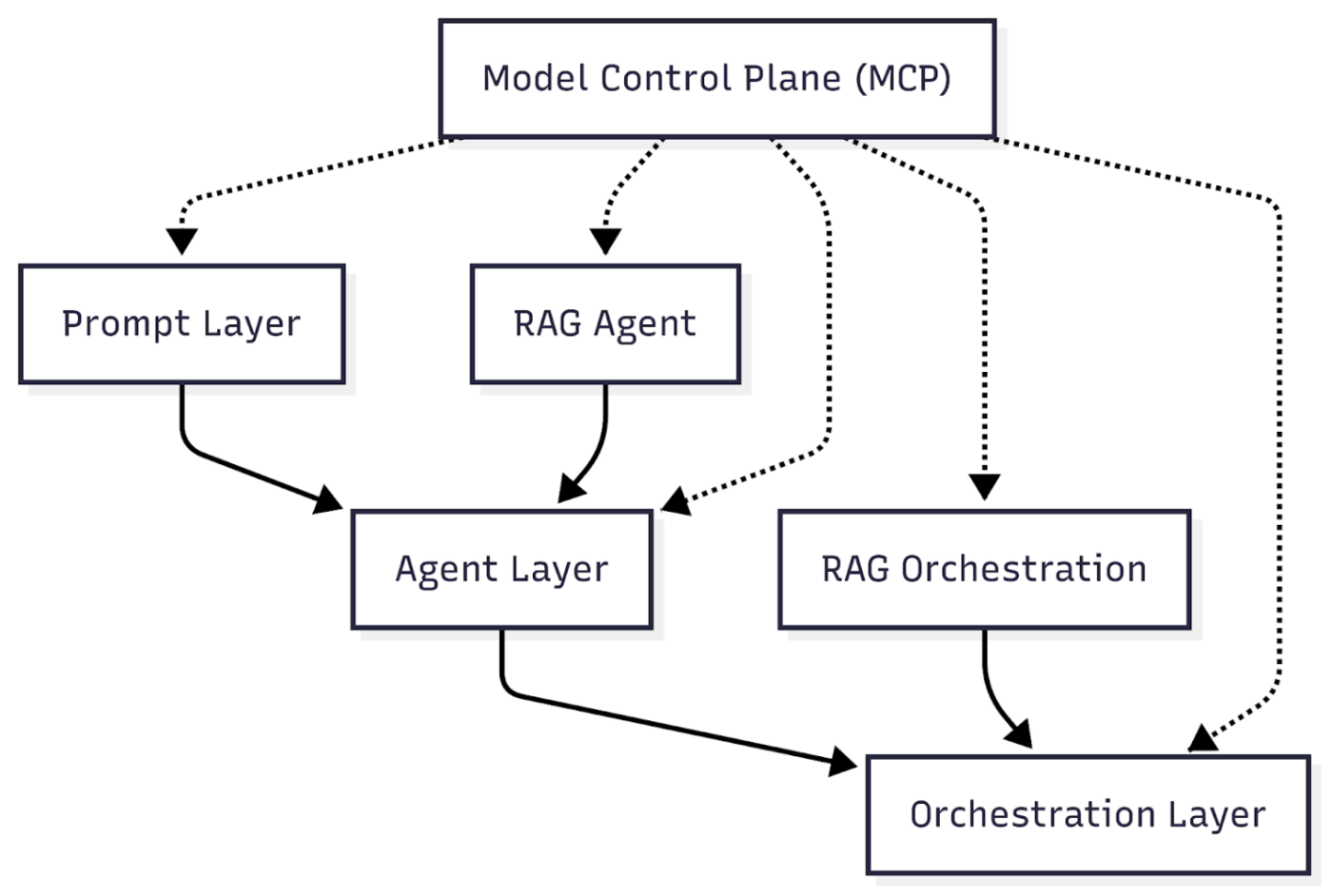
Model Control Plane (MCP): Operating System for LLMsAs organizations move from experimental LLM prototypes to production-scale systems, ad-hoc management quickly breaks down. The answer is the Model Control Plane (MCP): a centralized, policy-driven layer that governs the entire lifecycle of models, agents, prompts, and orchestration workflows. In short, MCP is to LLM delivery what Kubernetes is to microservices, an operating system for reliable, secure, and auditable AI infrastructure.
Why is MCP a Must-HaveWithout an MCP:
- Sprawl: Models, agents, and prompts proliferate in uncontrolled ways - across teams, environments, and business units.
- Untracked changes: Updates happen out of band; version mismatches, silent regressions, and configuration drift become daily risks.
- Security and compliance gaps: No single point for audit, access control, or policy enforcement. Sensitive data or experimental models slip through the cracks.
With an MCP:
- Centralized versioning: Every model, agent, prompt, and workflow is tracked, versioned, and rolled back as needed.
- Lifecycle management: From initial deployment through testing, promotion, and deprecation, MCP enforces process and transparency.
- Security and access: Unified RBAC (role-based access control), policy enforcement, and audit logs at every touchpoint.
- Audit and compliance: End-to-end traceability for every response - what models and data were used, by whom, and when.
- Model Registry: Tracks all models (foundation, fine-tuned, experimental), their versions, provenance, and deployment status.
- Prompt & Agent Management: Central store for all prompt templates and agent logic, including version history and usage metadata.
- Workflow Control: Registers and monitors all orchestration pipelines - enabling upgrades, A/B testing, and staged rollouts.
- Policy Enforcement: Sets organization-wide rules for privacy, safety, cost limits, and compliance (e.g., regional restrictions, output filters).
- Monitoring & Alerting: System-wide dashboards, usage stats, and automated alerts for drift, cost spikes, or security violations.
- Declarative configs: Treat all model, agent, and workflow definitions as code - managed via git, CI/CD, and deployment pipelines.
- Immutable versions: No silent “in-place” changes. Rollbacks and rollforwards are explicit, tested, and auditable.
- Granular access control: Assign clear roles for who can deploy, update, or retire models and workflows.
- Automated testing and promotion: Staging environments, automated evals, and user acceptance gates before production rollout.
MCP is not a luxury - it’s the foundation that separates demo projects from production LLM systems. The best architectures treat control, visibility, and safety as first-class features, not afterthoughts. With an effective MCP, organizations unlock safe scaling, rapid innovation, and ironclad auditability - essential in any regulated or mission-critical environment.
Real-World Problems & Pitfalls (Challenges & Solutions)No LLM-powered system survives contact with production unchanged. The real world quickly exposes blind spots in even the best architectures. Understanding and planning for these failure points and building robust, testable systems is what separates reliable AI from demo-ware.
Common Failure Points in LLM Architectures- Hallucinations: LLMs can generate outputs that sound correct but are factually wrong, fabricated, or even dangerous.
- Error Cascades: An early mistake (e.g., a bad retrieval or prompt misinterpretation) propagates through chained agents or workflow steps, multiplying downstream errors.
- State Loss: Poor management of conversation, context, or workflow state leads to dropped threads, context resets, or inexplicable “amnesia” in user-facing applications.
- Privacy Leaks: Sensitive data may be inadvertently included in prompts, logs, or outputs - exposing PII or business secrets.
- Cost Runaway: Inefficient prompts, uncontrolled token usage, and recursive agent calls can spiral operational costs far beyond initial estimates.
- Unit & Integration Testing: Create representative input/output suites for every prompt, agent, and workflow. Simulate edge cases, ambiguous queries, and “stress test” the stack.
- Continuous Output Evaluation: Use automated metrics (accuracy, relevance, toxicity, completeness) and human-in-the-loop review. Track drift over time as models or prompts evolve.
- Golden Set Monitoring: Maintain a set of “canonical” queries with expected answers. Alert on deviations.
- Structured Output & Parsing: Where possible, force LLMs to produce machine-parseable outputs (e.g., JSON, tables) for automated validation and downstream processing.
- A/B Testing & Staged Rollouts: Always deploy new workflows or model versions behind feature flags, with rollback options and impact measurement.
- Don’t trust “happy path” demos: Production users and data will always find the edge cases. Systems that look robust in isolated tests often collapse under real-world variety and scale.
- Over-reliance on LLM “intuition”: When LLMs are allowed to guess or improvise outside of validated context, risk of hallucination and policy violation skyrockets.
- Ignoring drift: LLMs, prompts, and underlying knowledge sources all evolve. Unmonitored systems degrade, producing outdated, irrelevant, or even dangerous outputs.
- Prompt sanitization: Scrub all inputs and context for PII or sensitive data before passing to external models or logging.
- Guardrails and filters: Use explicit policy enforcement: block unsafe outputs, require “I don’t know” responses when data is insufficient.
- Audit logging: Capture every prompt, context, model version, and response for compliance and post-incident review.
- Access controls: Limit who can modify prompts, deploy models, or access sensitive data within the stack.
Production-ready LLM systems are never “done.” They require continuous monitoring, regular validation, and proactive risk management. Invest in layered defenses: robust prompt engineering, agent design, orchestration, and a culture of operational humility. The companies that learn from their failures and share those lessons will set the bar for safe, effective AI delivery.
Practical Guide & Checklist: How to Start Without Messing UpBuilding production-ready LLM systems is deceptively easy to start and dangerously easy to derail. The difference between a working prototype and a scalable, maintainable solution is process, discipline, and an honest look at risk. Here’s a playbook for getting it right from day one.
Step 1: Define Your Real-World Use Case- What’s the business goal or user pain point?
- Is LLM the best approach, or is there a simpler deterministic alternative?
- Who are the actual users, and what does “success” look like for them?
- What data or documents must the system access? Where does up-to-date, authoritative knowledge live?
- Are there privacy or compliance boundaries? What can’t be exposed to the LLM?
- Start with a minimal, auditable knowledge base for initial experiments.
- Prompt Layer
- Agent Layer
- Orchestration Layer
- Model Control Plane
- Create challenging test cases and “red team” your own stack.
- Simulate user errors, ambiguous prompts, and adversarial inputs.
- Monitor output drift as models, data, or prompts change.
- Set up automated metrics: accuracy, relevance, cost, error rates, latency.
- Regularly review logs and user feedback - look for both false positives and false negatives.
- Plan for continuous refinement as usage scales and requirements evolve.
- Monolithic prompt logic: One huge prompt, no modularity, no version control.
- “It just works” mentality: Skipping testing, monitoring, or validation.
- Hardcoding knowledge: Bypassing retrieval -risking outdated, incomplete, or non-compliant outputs.
- No rollback or audit: Deploying model or workflow changes with no ability to trace, revert, or explain outcomes.
- Ignoring privacy/compliance: Exposing sensitive data, failing to document who can see or update what.
- □ Is your use case clear, valuable, and measurable?
- □ Do you have a minimal, secure knowledge base and data map?
- □ Are your prompts versioned, tested, and reviewed?
- □ Is your agent logic modular, with clear separation of responsibilities?
- □ Is orchestration explicit, with state and context managed outside the LLM?
- □ Is every part of your stack observable and auditable?
- □ Do you have robust validation and guardrails against bad outputs?
- □ Can you roll back or audit any change, prompt, or model update?
- □ Are cost, latency, and user feedback being tracked and reviewed?
- □ Are privacy and compliance needs understood and enforced?
Summary: Great LLM systems are not built by accident. They’re engineered - layer by layer, with discipline and humility. Every shortcut taken at the start becomes an expensive lesson later. Use this checklist, avoid common traps, and treat every early project as a foundation for long-term, scalable success.
Blind Spots & Strategic RisksEven the most experienced technology leaders can miss the true scale of the LLM-driven architectural shift. The reason isn’t a lack of intelligence or ambition - it’s that the patterns of the past no longer apply. Here’s what often gets overlooked, and how to reframe for a future built on language-driven AI.
Why Leaders Miss the Shift- LLM systems look deceptively simple. A working proof-of-concept is easy; scaling to enterprise-grade reliability is an entirely different discipline.
- “Toolbox” thinking persists. Leaders see LLMs as add-ons to existing architectures, not as a new foundational layer with unique risks and requirements.
- Focus on surface metrics. Early pilots succeed on speed or novelty, while technical debt, drift, and compliance holes quietly accumulate beneath the surface.
- Overconfidence in legacy practices. Traditional SDLC patterns, code review, or DevOps are necessary but insufficient - new disciplines like prompt engineering, retrieval management, and continuous validation are just as vital.
- Technical
- Business
- Compliance and Privacy
- Embrace continuous learning: The “right” architecture today may need to be replaced or refactored tomorrow. Teams must be ready to test, fail, and adapt fast.
- Institutionalize curiosity: Make it safe for engineers to ask “what if?” and to experiment with new stack components without penalty for rapid iteration or early mistakes.
- Value system-level thinking: Encourage teams to see the whole workflow: from prompt to retrieval, orchestration, validation, and back.
- Cross-functional upskilling: Support ongoing training in prompt engineering, retrieval/RAG, and operational monitoring, not just classic software practices.
- Treat LLM architecture as core infrastructure, not an experiment.
- Demand traceability, auditability, and robust monitoring from day one.
- Align incentives for teams to find, report, and fix issues early - reward proactive risk management, not just “heroic” firefighting.
- Build partnerships with compliance, privacy, and risk teams - don’t leave them out of LLM projects until it’s too late.
Summary: The biggest risk is assuming LLM adoption is “just another project.” In reality, it’s a long-term, foundational shift—one that will reward organizations able to unlearn, relearn, and adapt their architecture and culture to new rules of AI-powered delivery.
Self & Team Checklist: Are You Truly LLM-Ready?Use this checklist as a structured, no-nonsense audit of your LLM capabilities. It covers technical skills, process maturity, and cultural alignment - so you know exactly where to invest next.
1. Prompt Engineering- □ Do we have team members skilled in prompt design (instructional, few-shot, chain-of-thought, modular prompts)?
- □ Are prompts versioned, reviewed, and tested like code?
- □ Can we rapidly adapt or debug prompts as requirements or models change?
- □ Is our workflow layer explicit and modular (not hidden inside prompts)?
- □ Do we manage state, context, and agent coordination outside the LLM?
- □ Can we trace, monitor, and rollback workflow changes?
- □ Do we have RAG capabilities - using external knowledge bases, semantic search, or APIs?
- □ Is our data source pipeline curated, up-to-date, and auditable?
- □ Are outputs always grounded in retrieved, authoritative context?
- □ Are privacy boundaries enforced in prompts, data, and logs?
- □ Do we have automated guardrails, output validation, and policy enforcement?
- □ Is every step (prompt, agent, workflow) logged for audit and compliance?
- □ Do we track and forecast token/API spend at the prompt, agent, and workflow levels?
- □ Are cost spikes or runaway loops automatically detected and limited?
- □ Can we report real cost-to-value ratios for each LLM-driven feature?
- □ Are business goals, user needs, and success metrics clearly defined and tracked for every LLM use case?
- □ Do we review user feedback, output quality, and error reports regularly?
- □ Is there a mechanism to quickly act on feedback, update prompts, and evolve workflows?
- □ Are engineers, product leads, and business owners upskilled in LLM-centric thinking, not just classic software practices?
- □ Do we run regular reviews and “red team” exercises for LLM risk and quality?
- □ Does leadership treat LLM delivery as a strategic capability, not just a technical experiment?
- Any unchecked box is an action item or a risk.
- Assign owners and deadlines for closing each gap.
- Re-audit quarterly as your architecture, data, and business requirements evolve.
Summary: LLM adoption isn’t about checking a single box—it’s about continuous, cross-functional readiness. This checklist makes gaps visible, clarifies priorities, and ensures that LLMs become a real asset, not a liability, in your organization.
Conclusion: LLM Architecture as a Real FoundationThe age of large language models isn’t a passing trend or a set of “cool demos.” It’s a permanent shift in how we build, deliver, and operate intelligent software. LLMs, when architected with discipline and foresight, can unlock speed, adaptability, and value at a scale legacy tools simply can’t match. But getting there is a choice, not an accident.
What truly makes this shift fundamental is the arrival of a new architectural dimension: uncertainty. Unlike previous technology waves, unpredictability is now a core design constraint - present in every prompt, agent, orchestration layer, and especially in the limits of model attention. Engineering for LLMs means engineering for ambiguity and drift, not just for scale or performance. The teams that will succeed are those that learn to observe, manage, and even leverage this uncertainty - treating it as a first-class element of architecture, not a problem to be eliminated.
What’s Next for Leaders and Architects
Make LLM architecture a core part of your technology and business roadmap. Treat it as infrastructure, not an experiment. Insist on versioning, validation, monitoring, and continuous improvement.
- Champion new skills and roles. Invest in upskilling teams in prompt engineering, RAG, orchestration, and governance. Cross-functional expertise will separate winners from laggards.
- Start small - but start right. Pilot with real business cases, layered architectures, and explicit guardrails. Build the feedback loops, observability, and auditability from day one.
- Treat every failure as a lesson. Track what goes wrong, not just what works. Share learnings openly across teams and disciplines—this is how AI becomes safe and effective at scale.
- Stay adaptive. The pace of AI change isn’t slowing. Create a culture where architecture and process can evolve without drama - because what’s “best practice” today will shift again tomorrow.
Monday-Morning Actions
- Identify one area where you can add versioning, validation, or monitoring to your LLM stack this week.
- Schedule a team session to map your current LLM workflows - highlight risks, unknowns, and hidden dependencies.
- Assign one owner for LLM readiness: someone who can drive audits, training, and continuous improvement.
Final Thought:
The future of LLM-driven systems will not be won by whoever has the most tokens or the newest foundation model. The winners will be those who treat LLM architecture as a craft, continuously upskill their teams, and orchestrate every layer for reliability, safety, and speed. Building real-world value with AI is a team sport now - one that rewards those who invest in mastering the stack, not just chasing model specs. Mastering this new architectural dimension, where uncertainty is an ever-present variable - will define the organizations that endure, adapt, and lead in the next decade of intelligent software.
PMO & Delivery Head
Vitalii Oborskyi - https://www.linkedin.com/in/vitaliioborskyi/