and the distribution of digital products.
Stop Prompting, Start Engineering: 15 Principles to Deliver Your AI Agent to Production
\
IntroductionAt first, you just try to communicate with ChatGPT via API, throw in a couple of lines of context, and feel amazed that it responds at all. Then you want it to do something useful. Then — to do it reliably. Eventually — to do it without you.
That’s how an agent is born.
If you’ve also spent the past year cobbling together agents from scripts and wrappers, experimenting and tinkering, and you’re still searching for a cleaner, more sustainable way to build them — this article is for you. I’ve wandered through repos and forums, repeatedly asking myself, “How are others doing it?” > I kept what stuck — what actually felt right after some real use, and gradually distilled a set of core principles for turning a cool idea into a production-ready solution.
This isn’t a manifesto. Think of it as a practical cheat sheet — a collection of engineering principles that help guide an agent from the sandbox to production: from a simple API wrapper to a stable, controllable, and scalable system.
Disclaimer
In this article (Building effective agents), Anthropic defines an agent as a system where LLMs dynamically direct their own processes and tool usage, maintaining control over how they accomplish tasks. Systems where LLMs and tools are orchestrated through predefined code paths they call Workflows. Both are part of a broader concept - Agent Systems.
In this text, Agent = Agent system, where for the sake of stability and control I will more often lean towards Workflows. I hope that in the near future there will be 1-2 more turns of the evolution and true Agents will be ubiquitous, but for now this is not the case
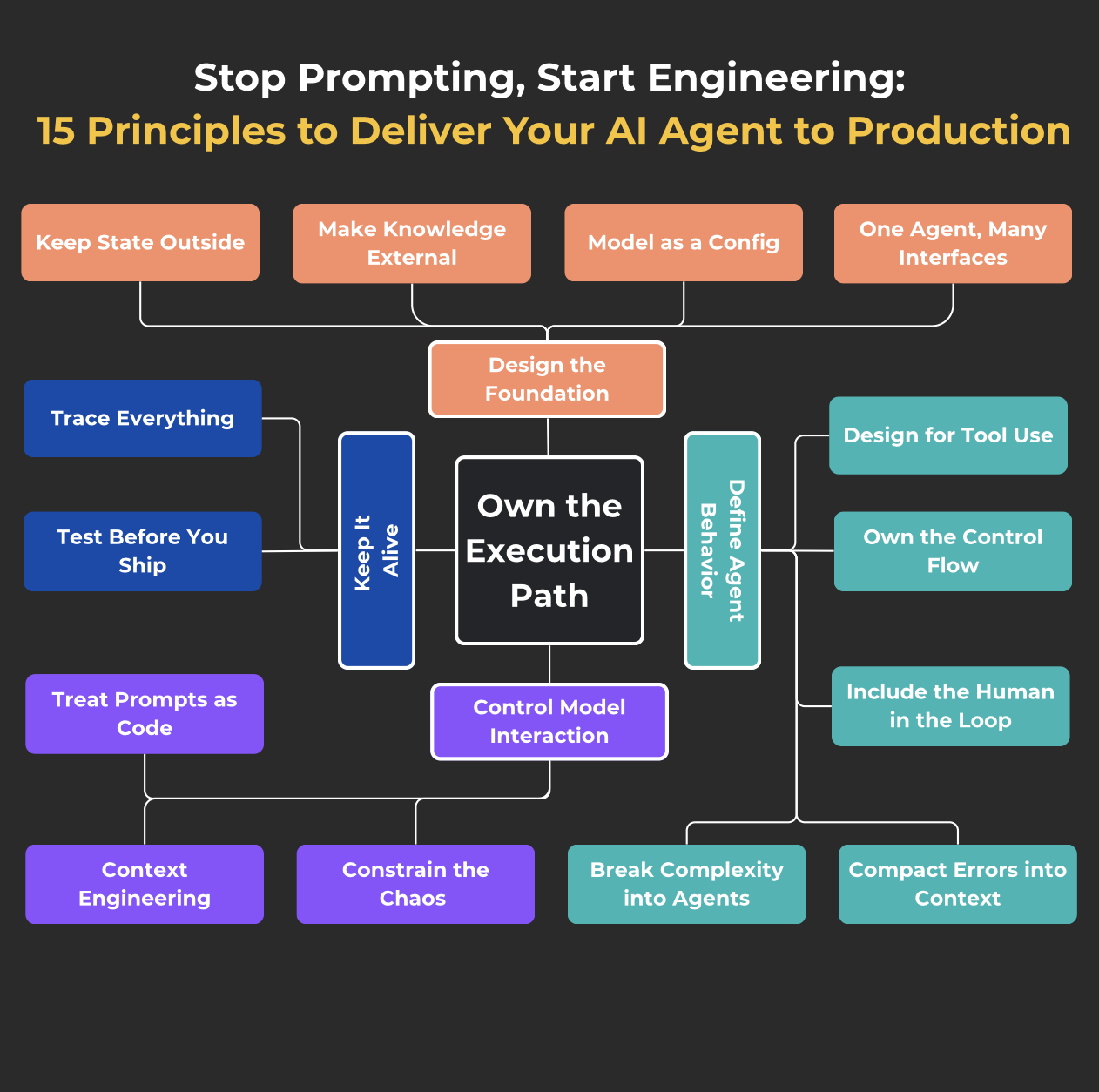
1. Design the FoundationEarly versions of agents usually come together fast: a few functions, a couple of prompts — and hey, it works.
“If it works, why make it complicated?”
In the beginning, everything seems stable. The agent responds, executes code, behaves sensibly. But once you switch the model, restart the system, or plug in a new interface — suddenly it becomes unstable, unpredictable, hard to debug.
And often, the root cause isn’t in the logic or the prompts, but much earlier: broken memory management, hardcoded staff, no way to resume sessions, or a single rigid entry point.
This section walks through four key principles that will help you build a solid foundation — one that everything else can safely grow on top of.
1. Keep State OutsideProblem:
- You can’t resume the process. If the agent gets interrupted (a crash, a timeout, whatever), it should be able to pick up exactly where it left off.
- Reproducibility is limited. You need a way to precisely reproduce what happened — for testing, debugging and other such pleasures.
This one’s not strictly a problem, but still:
- Parallelization. Sooner or later you’ll want to parallelize the agent’s logic. Maybe it needs to compare multiple options mid-dialogue (“Which of these is better?”). Maybe you want it to branch. Who knows — you will.
(Memory is a whole separate issue — we’ll get to that soon)
Solution: Move state outside the agent — into a database, a cache, a storage layer — even a JSON file will do.
Checklist:
- The agent can be launched from any step, having only a session_id — the session identifier — and external state (for example, saved steps in a database or JSON file). At any stage, you can interrupt the agent's work, restart it (even after changing something under the hood), and it will work as if nothing happened
- Test case: an interrupted agent doesn't lose context, after restart the result is the same
- State is serializable at any moment without loss of functionality
- You can feed the state to multiple instances in parallel in the middle of a dialogue
Problem: LLMs don't remember. Even within a single session, the model can forget what you've already explained, mix up stages, lose the thread of conversation, or start "filling in" details that weren't there. And it seems like time goes on, the context window grows bigger and bigger, delighting us with new possibilities. LinkedIn is full of posts where people compare which book or how many hours of YouTube's video now fit into the new model version. But still, LLMs don't remember and you should be prepared.
Especially if:
- dialogue is long
- documents are large
- instructions are complex
- and tokens are still not infinite
Even with increasing context windows (8k, 16k, 128k…), problems remain:
- "Lost in the middle" — the model pays more attention to the beginning and end (and can loose details from the middle)
- Cost — more tokens = more money;
- And it still doesn't fit. Which means there will be loss, distortion, or hallucinations. As long as transformers work on self-attention with quadratic complexity (O(n²)), this limitation will be with us.
Solution: Separate "working memory" from "storage" — like in classical computing systems. The agent should be able to work with external memory: store, retrieve, summarize, and update knowledge outside the model. There are several architectural strategies, and each has its boundaries.
Approaches
Memory Buffer
Stores the last k messages. Take for quick prototyping.
+ simple, fast, sufficient for short tasks
- loses important info, doesn't scale, doesn't remember "yesterday"
\ Summarization Memory
Compresses history to fit more.
+ token savings, memory expansion
- distortions, loss of nuances, errors in multi-step compression
\ RAG (Retrieval-Augmented Generation)
Pulls knowledge from external databases. Most of the time you'll be here.
+ scalable, fresh, verifiable
- complex setup, sensitive to retrieval quality, latency
\ Knowledge Graphs
Structured connections between entities and facts. Always elegant, sexy and hard, you'll end up doing RAG anyway.
+ logic, explainability, stability
- high barrier to entry, complexity of LLM integration
Checklist:
- All conversation history is accessible in one place (outside the prompt)
- Knowledge sources are logged and can be reused
- History scales without risk of exceeding the context window
Problem: LLMs are rapidly evolving; Google, Anthropic, OpenAI, etc. constantly release updates, racing against each other across different benchmarks. This is a feast for us as engineers, and we want to make the most of it. Our agent should be able to easily switch to a better (or conversely, cheaper) model seamlessly.
Solution:
- Implement modelid configuration: Use a modelid parameter in configuration files or environment variables to specify the model being used.
- Use abstract interfaces: Create interfaces or wrapper classes that interact with models through a unified API.
- Apply middleware solutions (carefully—we'll talk about frameworks a bit later)
Checklist:
- Model replacement doesn't affect the rest of the code and doesn't impact agent functionality, orchestration, memory, or tools
- Adding a new model requires only configuration and, optionally, an adapter (a simple layer that brings the new model to the required interface)
- You can easily and quickly switch models. Ideally—any models, at minimum—switching within a model family
Problem: Even if initially the agent is intended to have only one communication interface (for example, UI), you'll eventually want to give users more flexibility and convenience by adding interaction through Slack, WhatsApp, or, dare I say it, SMS - whatever. An API might turn into a CLI (or you'll want one for debugging). Build this into your design from the start; make it possible to use your agent wherever it's convenient.
Solution: Creating a unified input contract: Develop an API or other mechanism that will serve as a universal interface for all channels. Store channel interaction logic separately.
Checklist:
Agent is callable from CLI, API, UI
All input goes through a single endpoint/parser/schema
All interfaces use the same input format
No channel contains business logic
Adding a new channel = only an adapter, no changes to core
\
\
While there's only one task, everything is simple, as in the posts of AI evangelists. But as soon as you add tools, decision-making logic, and multiple stages, the agent turns into a mess.
It loses track, doesn't know what to do with errors, forgets to call the right tool—and you're left alone again with logs where "well, everything seems to be written there."
To avoid this, the agent needs a clear behavioral model: what it does, what tools it has, who makes decisions, how humans intervene, and what to do when something goes wrong.
This section covers principles that will help you give your agent a coherent action strategy instead of hoping "the model will figure it out somehow."
5. Design for Tool UseProblem: This point might seem obvious, but you still encounter agents built on "Plain Prompting + raw LLM output parsing." It's like trying to control a complex mechanism by pulling random strings and hoping for the best. When LLMs return plain text that we then try to parse with regex or string methods, we face:
- Brittleness: The slightest change in LLM response wording (a word added, phrase order changed) can break the entire parsing. This leads to a constant "arms race" between your parsing code and model unpredictability.
- Ambiguity: Natural language is inherently ambiguous. What seems obvious to a human can be a puzzle for a parser. "Call John Smith"—which of the three John Smiths in your database? What's his number?
- Maintenance complexity: Parsing code grows, becomes tangled and hard to debug. Each new agent "skill" requires writing new parsing rules.
- Limited capabilities: It's hard to make the model reliably call multiple tools or pass complex data structures through simple text output.
Solution: The model returns JSON (or another structured format)—the system executes.
The key idea here is to leave the responsibility for interpreting user intent and choosing tools to the LLM, while still assigning the execution of that intent to the system through a clearly defined interface.
Fortunately, practically all providers (OpenAI, Google, Anthropic, or whoever else you prefer) support so-called "function calling" or the ability to generate output in a strictly defined JSON format.
Just to refresh how this works:
- Tool description: You define functions (tools) as JSON Schema with name, description, parameters. Description is critically important—the model relies on it.
- Passing to LLM: On each call, the model receives tool schemas along with the prompt.
- Model output: Instead of text, the model returns JSON with:
- name of the function to call
- arguments—parameters according to schema
- Execution: Code validates JSON and calls the appropriate function with parameters.
- Model response (optional): Execution result is passed back to LLM for final response generation.
Important: Tool descriptions are also prompts. Unclear description = wrong function choice.
What to do without function calling?
If the model doesn't support tool calls or you want to avoid them for some reason:
- Ask the model to return JSON in the prompt. Be sure to specify the format; you can add examples.
- Parse the response and validate it with something like Pydantic. There are real fans of this approach.
Checklist:
- Response is strictly formalized (e.g., JSON)
- Schemas are used (JSON Schema or Pydantic)
- Validation is applied before function calls
- Generation errors don't cause breakage (format error handling exists)
- LLM = function choice, execution = code
Problem: Usually agents work as "dialogues"—first the user speaks, then the agent responds. It's like playing ping-pong: hit-response. Convenient, but limiting.
Such an agent cannot:
- Do something on its own without a request
- Perform actions in parallel
- Plan steps in advance
- Take multiple steps in sequence
- Check progress and return to failed steps
Instead, the agent should manage its own "execution flow"—decide what to do next and how to do it. This is like a task scheduler: the agent looks at what needs to be done and executes steps in order.
This means the agent:
- decides when to do something on its own
- can take steps one after another
- can retry failed steps
- can switch between tasks
- can work even without direct requests
Solution: Instead of letting the LLM control all the logic, we extract the control flow into code. The model only helps within steps or suggests the next one. This is a shift from "writing prompts" to engineering a system with controlled behaviour.
Let's look at three popular approaches:
1. FSM (Finite State Machines)
\
- What it is: Task broken down into states and clear transitions.
- LLM: Determines the next step or acts within a state.
- Pros: Simplicity, predictability, good for linear scenarios.
- Tools: StateFlow, YAML configurations, State Pattern.
2. DAG (Directed Graphs)
\
- What it is: Non-linear or parallel tasks as a graph: nodes are actions, edges are dependencies.
- LLM: Can be a node or help with plan construction.
- Pros: Flexibility, parallelism, visualizable.
- Tools: LangGraph, Trellis, LLMCompiler, custom DAG diagrams.
3. Planner + Executor
\
- What it is: LLM builds a plan, code or other agents execute it.
- LLM: "Big" one plans, "small" ones execute.
- Pros: Separation of concerns, cost control, scalability.
- Tools: LangChain Plan-and-Execute.
Why this matters:
\
- Increases controllability, reliability, scalability.
- Allows combining different models and speeding up execution.
- Task flow becomes visualizable and testable.
Checklist:
- Uses FSM, DAG, or scenario with explicit transitions
- Model decides what to do but doesn't control the flow
- Behavior can be visualized and tested
- Error handling is built into the flow
Problem: Even if an agent uses structured tools and has a clear control flow, full autonomy of LLM agents in the real world is still more of a dream (or nightmare, depending on context). LLMs don't possess true understanding and aren't accountable for anything. They can and will make suboptimal decisions. Especially in complex or ambiguous situations.
Main risks of full autonomy:
- Permanent mistakes: The agent might perform actions with serious consequences (delete data, send an incorrect message to an important client, start a robot uprising).
- Compliance violations: The agent might accidentally violate internal regulations, legal requirements, or hurt user feelings (if that wasn't the plan, ignore this point).
- Lack of common sense and ethics: LLMs might miss social nuances or act against "common sense."
- Loss of user trust: If the agent makes frequent mistakes, users will stop trusting it.
- Audit and accountability complexity: Who's to blame when an autonomous agent "screws up"?
Solution: ~~Strategic summoning of Carbon-based lifeforms~~ Integrate humans into the decision-making process at key stages.
HITL Implementation Options
1. Approval Flow
- When: action is critical, expensive, irreversible
- How: agent formulates a proposal and waits for confirmation
2. Confidence-aware Routing
- When: model is uncertain
- How:
- self-assessment (logits, LLM-as-a-judge, P(IK))
- escalation when confidence falls below threshold
3. Human-as-a-Tool
- When: insufficient data or unclear request formulation
- How: agent asks for clarification (e.g., HumanTool in CrewAI)
4. Fallback Escalation
- When: repeated error or unresolvable situation
- How: task is passed to operator with context
5. RLHF (Human Feedback)
- When: for model improvement
- How: human evaluates responses, they go into training
Checklist:
- Actions requiring approval are defined
- There's a mechanism for confidence assessment
- Agent can ask humans questions
- Critical actions require confirmation
- There's an interface for inputting responses
Problem: The standard behavior of many systems when an error occurs is either to "crash" or simply report the error and stop. For an agent that should autonomously solve tasks, this isn't exactly the best behavioral model. But we also don't want it to hallucinate around the problem.
What we'll face:
- Brittleness: Any failure in an external tool or unexpected LLM response can stop the entire process or lead it astray.
- Inefficiency: Constant restarts and manual intervention eat up time and resources.
- Inability to learn (in the broad sense): If the agent doesn't "see" its errors in context, it can't try to fix them or adapt its behavior.
- Hallucinations. Again.
Solution: Errors are included in the prompt or memory. The idea is to try implementing some kind of "self-healing." Agent should at least try to correct its behavior and adapt.
Rough flow:
- Understanding the error
- Self-correction:
- Self-correction mechanisms: Error Detection, Reflection, Retry Logic, Retry with changes (Agent can modify request parameters, rephrase the task, or try a different tool)
- Impact of reflection type: More detailed error information (instructions, explanations) usually leads to better self-correction results. Even simple knowledge of previous errors improves performance.
- Internal Self-Correction: Training LLMs for self-correction by introducing errors and their fixes into training data.
- Request human help: If self-correction fails, the agent escalates the problem to a human (see Principle 7).
Checklist:
- Previous step's error is saved to context
- Retry logic exists
- Fallback/human escalation is used for repeated failures
Problem: Let's back to the key LLM limitation (that context window thing), but look at this problem from another angle. The bigger and more complex the task, the more steps it will take, which means a longer context window. As context grows, LLMs are more likely to get lost or lose focus. By focusing agents on specific domains with 3-10, maybe maximum 20 steps, we maintain manageable context windows and high LLM performance.
Solution: Use smaller agents targeted at specific tasks. One agent = one task; orchestration from above.
Benefits of small, focused agents:
- Manageable context: Smaller context windows mean better LLM performance
- Clear responsibilities: Each agent has a well-defined scope and purpose
- Better reliability: Less chance of getting lost in complex workflows
- Simpler testing: Easier to test and validate specific functionality
- Improved debugging: Easier to identify and fix problems when they arise
Unfortunately, there's no clear heuristic for understanding when a piece of logic is already big enough to split into multiple agents. I'm pretty sure that while you're reading this text, LLMs have gotten smarter somewhere in labs. And they keep getting better and better, so any attempt to formalize this boundary is doomed from the start. Yes, the smaller the task, the simpler it is, but the bigger it gets, the better the potential is realized. The right intuition will only come with experience. But that's not certain.
Checklist:
Scenario is built from microservice calls
Agents can be restarted and tested separately
Agent = minimal autonomous logic. You can explain what it does in 1-2 sentences.
\
\
The model handles generation. Everything else is on you.
How you formulated the request, what you passed in context, what instructions you gave—all this determines whether the result will be coherent or "creative."
LLMs don't read minds. They read tokens.
Which means any input error turns into an output bug—just not immediately noticeable.
This section is about not letting everything drift: prompts = code, explicit context management, constraining the model within boundaries. We don't hope that the LLM will "figure it out on its own."
10. Treat Prompts as CodeProblem: A very common pattern, especially among folks without ML or SE background, is storing prompts directly in code. Or at best, unsystematic storage in external files.
This approach leads to several maintenance and scaling difficulties:
- Navigation, understanding, and modification become complicated as project complexity and number of prompts grow.
- Without explicit versioning, it's very hard to track prompt evolution, reasons for changes, and roll back to previous stable versions in case of performance degradation.
- Inefficient improvement and debugging process: Prompt optimization without objective metrics and testing becomes a subjective and labor-intensive process with unstable results.
- Perception by other team members becomes complicated, including (and especially) future you.
Solution: Prompts in this context are not much different from code and the same basic engineering practices should be applied to them
This implies:
- Store separately and systematically, using specialized files (like .txt, .md, .yaml, .json) or even template management systems (e.g., Jinja2, Handlebars, or specialized tools like BAML).
- Explicit prompt versioning. You can even do A/B tests with different versions after this.
- Testing. You heard that right.
- This could be something like unit tests, where you compare LLM responses to specific inputs against reference answers or expected characteristics depending on the prompt
- Evaluation datasets
- Format compliance checks and presence/absence of key elements - For example, if a prompt should return JSON, the test can validate its structure
- Even LLM-as-a-judge if your project and design justify it.
We'll talk about testing in more detail in the principe 14.
Checklist:
- Prompts are stored in separate files, separate from business logic
- There's diff and change history
- Tests are used (as needed)
- (Optional) How about prompt review as part of code review?
Problem: We've already discussed the "forgetfulness" of LLMs, partially solving this by offloading history to external memory and using different agents for different tasks. But that's not all. I propose we also consider explicit context window management (and here I'm not just talking about compressing history to fit the optimal size or including errors from previous steps in the context).
Standard formats aren't always optimal: A simple list of messages in the "role-content" (system/user/assistant) format is the baseline, but it can be token-heavy, not informative enough, or poor at conveying the complex state of your agent.
Most LLM clients use the standard message format (a list of objects with role: "system", "user", "assistant", content, and sometimes tool_calls fields).
While this "works great for most cases," to achieve maximum efficiency (in terms of both tokens and the model's attention), we can approach context formation more creatively.
Solution: To engineer it. To treat the creation of the entire information package passed to the LLM as "Context Engineering." This means:
- Full Control: Taking full ownership for what information enters the LLM's context window, in what form, volume, and sequence.
- Creating Custom Formats: Not limiting ourselves to standard message lists. Developing our own, task-optimized ways of representing context. For example, you could consider using an XML-like structure to densely pack various types of information (messages, tool calls, their results, errors, etc.) into one or several messages.
- Holistic Approach: Viewing the context not just as a dialogue history, but as the sum total of everything the model might need: the immediate prompt, instructions, data from RAG systems, the history of tool calls, the agent's state, memory from other interactions, and even instructions on the desired output format.
(Instead of a checklist) How do you know when this makes sense?
If you're interested in any of the following:
- Information Density. Maximum meaning with minimum noise.
- Cost-Effectiveness. Reducing the number of tokens where we can get comparable quality for a lower price.
- Improved Error Handling.
- Security. Handling the inclusion of sensitive info, controlling it, filtering it, .and ending it all by outputting the classic "sorry, I'm just a squishy little large language model model" response.
Problem: We've already done a lot in the name of stability, but nothing is a silver bullet. This means it's worth looking at the most critical potential problems separately and explicitly taking out some "insurance".
In this principle, we think about:
- Possible Prompt Injection. If your agent will be communicating directly with a user, you must control what is fed as input. Depending on the type of user, you might get one who wants to break your flow and force the agent to ignore its initial goals, provide the wrong information, perform harmful actions, or generate malicious content.
- Sensitive Data Leakage. For the reason above, or led by "voices in its head," the agent might disclose important information, such as users' personal data, corporate secrets, etc.
- Generation of toxic or malicious content. If this is by design, ignore this point.
- Making things up when information is absent. The eternal pain.
- Going beyond permitted boundaries. Rise of the machines, remember? But seriously, in its reasoning process, the agent might arrive at very non-trivial solutions, not all of which will be within the scope of normal behaviour.
The security and grounding of an LLM agent isn't a single measure, but a multi-layered system of protection ("defense-in-depth") that covers the entire interaction lifecycle. The threats are diverse, and no single method of protection is a panacea. Effective protection requires a combination of techniques.
Solution: We must commit to a multi-layered defense system, thinking through and explicitly handling all corner cases and potential scenarios, and having a clear response ready for whatever might happen.
In a basic setup, you should consider:
Secure Inputs.
Check for known attack-indicator phrases (e.g., "ignore all previous instructions"). It sometimes makes sense to combat potential obfuscation.
Try to determine the user's intent separately. You can use another LLM for this, to analyze the input for the current one.
Control input from external sources, even if they are your own tools.
Guarded Actions. Control the privileges of both the agent and its tools (granting the minimum necessary), clearly define and limit the list of available tools, validate parameters at the input to tools, and enable Principle #7 (Human in the Loop).
Output Moderation. Design a system of checks for what the model outputs, especially if it goes directly to the user. These can be checks for relevance (ensuring the model uses what's in the RAG and doesn't just make things up) as well as checks for general appropriateness. There are also ready-made solutions (e.g., the OpenAI Moderation API).
The final system, however, depends on your tasks and your risk assessment. In the checklist, we'll try to sketch out some options.
Checklist:
User input validation is in place.
For tasks requiring factual information, the data within the RAG is used.
The prompt for the LLM in a RAG system explicitly instructs the model to base its answer on the retrieved context.
LLM output filtering is implemented to prevent PII (Personally Identifiable Information) leakage.
The response includes a link or reference to the source.
LLM output moderation for undesirable content is implemented.
The agent and its tools operate following the principle of least privilege.
The agent's actions are monitored, with HITL (Human-in-the-Loop) for critical operations.
\
\
An agent that "kinda works" is a bug with a delayed effect.
In prod, not everything breaks at once. And you don't find out about it instantly. Sometimes, you don't find out at all.
This section is about the engineering habit of seeing what's happening and checking that everything is still working. Logs, tracing, tests—everything that makes an agent's behavior transparent and reliable, even when you're sleeping or developing your next agent.
13. Trace EverythingProblem: One way or another, you will constantly face situations where the agent doesn't work as you expected. During development, testing, making changes, or during normal operation. This is inevitable, and at the moment, it's normal to some extent. This means you're doomed to spend hours and days debugging, trying to understand what's wrong, reproducing the issue, and fixing it. I'd like to think that by this point you've already implemented Principle #1 (Keep State Outside) and #8 (Compact Errors into Context). In most cases, that will be enough to make your life much simpler. Some other principles will also indirectly help here.
Even so (and especially if you've decided not to bother with them for now), it makes a lot of sense to think about debugging in advance and save yourself time and nerves in the future by adhering to this principle.
Solution: Log the entire path from request to action. Even if you already have logs for individual components, tracing the entire chain can be a hassle. Even if you're a big fan of puzzles or Lego, at some point, it will stop being fun. Therefore, logs must exist, they must be end-to-end, and they must cover everything.
Why it's needed:
- Debugging — Quickly find where things went wrong. This is the reason this principle exists.
- Analytics — See where the bottlenecks are and how to improve.
- Quality Assessment — See how changes affect behavior.
- Reproducibility — You can precisely reconstruct the steps.
- Auditing — A log of all agent decisions and actions.
The basic "gentleman's set" looks like this:
- Input: The initial user request, parameters received from the previous step.
- Agent State: Key state variables of the agent before executing the step.
- Prompt: The full text of the prompt sent to the LLM, including system instructions, dialogue history, retrieved RAG context, tool descriptions, etc.
- LLM Output: The full, raw response from the LLM, before any parsing or processing.
- Tool Call: If the LLM decided to call a tool – the name of the tool and the exact parameters it was called with (according to the structured output).
- Tool Result: The response that the tool returned, including both successful results and error messages.
- Agent's Decision: What decision the agent made based on the LLM's response or the tool's result (e.g., what next step to perform, what answer to give the user).
- Metadata: Step execution time, the LLM model used, the cost of the call (if available), the code/prompt version.
Note: Look into existing tracing tools; under certain conditions, they will make your life much easier. LangSmith, for example, provides detailed visualization of call chains, prompts, responses, and tool usage. You can also adapt tools like Arize, Weights & Biases, OpenTelemetry, etc. for your needs. But first, see Principle #15.
Checklist:
- All agent steps are logged (your version of the "gentleman's set").
- Steps are linked by a session_id and a step_id.
- There is an interface to view the entire chain.
- The prompt sent to the LLM can be reproduced at any stage.
Problem: By this point, you most likely have some kind of practically finished solution. It works, maybe even just the way you wanted. Ship it to prod? But how do we ensure it keeps working? Even after the next minor update? Yes, I'm leading us to the topic of testing.
Obviously, updates in LLM systems, just like in any other—be it changes to the application code, updates to datasets for fine-tuning or RAG, a new version of the base LLM, or even minor prompt adjustments—often lead to unintentional breaks in existing logic and unexpected, sometimes degrading, agent behavior. Traditional software testing approaches prove to be insufficient for comprehensive quality control of LLM systems. This is due to a number of risks and characteristics specific to large language models:
- Model Drift. You haven't done anything, but performance has dropped over time. Maybe the provider updated their model, maybe the nature of the input data has changed (data drift)—what worked yesterday might stop working today.
- Prompt Brittleness. Even a small change to a prompt can break the established logic and distort the output.
- Non-determinism of LLMs: As you know, many LLMs are non-deterministic (especially with temperature > 0), meaning they will generate different responses to the same input on each call. This complicates the creation of traditional tests that expect an exact match and makes reproducing errors more difficult.
- Difficulty in reproducing and debugging errors. It will be easier for you if you've implemented the first principle, but reproducing a specific error for debugging can be difficult even with fixed data and states.
- "The Butterfly Effect." In complex systems, updating a single element (like a model or a prompt) can cascade through a chain of APIs, databases, tools, etc., and lead to a change in behavior elsewhere.
- Hallucinations.
…and I suppose we could go on. But we already understand that traditional tests, focused on verifying explicit code logic, are not fully capable of covering these issues.
Solution: We'll have to devise a complex, comprehensive approach that covers many things, combining classic and domain-specific solutions. This solution should address the following aspects:
- Multi-level testing: A combination of different test types targeting various aspects of the system: from low-level unit tests for individual functions and prompts to complex scenarios that verify the agent's end-to-end workflow and user interaction.
- Focus on LLM behavior and quality: Testing should evaluate not only functional correctness but also qualitative characteristics of LLM responses, such as relevance, accuracy, coherence, absence of harmful or biased content, and adherence to instructions and a given style.
- Regression and quality tests that include "golden datasets" containing diverse input examples and reference (or acceptable ranges of) outputs.
- Automation and integration into CI/CD.
- Human-in-the-loop evaluation: Specific stages of LLM-eval should involve a human for calibrating metrics and reviewing complex or critical cases.
- An iterative approach to prompt development and testing: Prompt engineering should be treated as an iterative process where each version of a prompt is thoroughly tested and evaluated before implementation.
- Testing at different levels of abstraction:
- Component testing: Individual modules (parsers, validators, API calls) and their integration.
- Prompt testing: Isolated testing of prompts on various inputs.
- Chain/Agent testing: Verifying the logic and interaction of components within an agent.
- End-to-end system testing: Evaluating the completion of full user tasks.
Checklist:
Logic is broken down into modules: functions, prompts, APIs—everything is tested separately and in combination.
Response quality is checked against benchmark data, evaluating meaning, style, and correctness.
Scenarios cover typical and edge cases: from normal dialogues to failures and provocative inputs.
The agent must not fail due to noise, erroneous input, or prompt injections—all of this is tested.
Any updates are run through CI and monitored in prod—the agent's behavior must not change unnoticed.
This is a meta-principle; it runs through all the ones listed above.
Fortunately, today we have dozens of tools and frameworks for any task. This is great, it's convenient, and it's a trap.
Almost always, choosing a ready-made solution means a trade-off: you get speed and an easy start, but you lose flexibility, control, and, potentially, security.
This is especially critical in agent development, where it's important to manage:
- the unpredictability of LLMs,
- complex logic for transitions and self-correction,
- being ready for the system's adaptation and evolution, even if its core tasks remain unchanged.
Frameworks bring inversion of control: they decide for you how the agent should work. This can simplify a prototype but complicate its long-term development.
Many of the principles described above can be implemented using off-the-shelf solutions—and this is often justified. But in some cases, an explicit implementation of the core logic takes a comparable amount of time and provides incomparably more transparency, manageability, and adaptability.
The opposite extreme also exists—over-engineering, the desire to write everything from scratch. This is also a mistake.
This is why the key is balance. The engineer chooses for themselves: where it's reasonable to rely on a framework, and where it's important to maintain control. And they make this decision consciously, understanding the cost and consequences.
You have to remember: the industry is still taking shape. Many tools were created before current standards emerged. Tomorrow, they might become obsolete—but the limitations baked into your architecture today will remain.
\
ConclusionOkay, we've gone over 15 principles that, experience shows, help turn the initial excitement of "it's alive!" into confidence that your LLM agent will work in a stable, predictable, and useful way under real-world conditions.
You should consider each of them to see if it makes sense to apply it to your project. In the end, it's your project, your task, and your creation.
Key takeaways to carry with you:
- An engineering approach is key: Don't rely on the "magic" of LLMs. Structure, predictability, manageability, and testability are your best friends.
- The LLM is a powerful component, but still just a component: Treat the LLM as a very smart, but nevertheless, single component of your system. Control over the overall process, data, and security must remain with you.
- Iteration and feedback are the keys to success: It's rare to create the perfect agent on the first try. Be prepared for experiments, measurements, error analysis, and continuous improvement—of both the agent itself and your development processes. Including a human in the loop (HITL) isn't just about security; it's also about having an invaluable source of feedback for learning.
- Community and openness: The field of LLM agents is evolving rapidly. Keep an eye on new research, tools, and best practices, and share your own experiences. Many of the problems you'll face, someone has already solved or is solving right now.
I hope you've found something new and useful here, and maybe you'll even want to come back to this while designing your next agent.